Interpretation and Trust: Designing Model-Driven Visualizations for Text Analysis
abstract
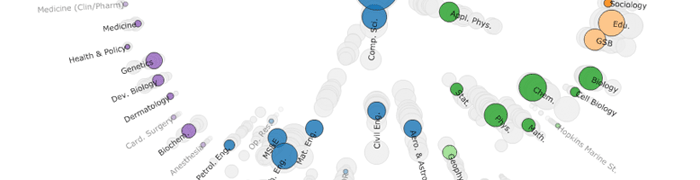
Statistical topic models can help analysts discover patterns in large text corpora by identifying recurring sets of words and enabling exploration by topical concepts. However, understanding and validating the output of these models can itself be a challenging analysis task. In this paper, we offer two design considerations - interpretation and trust - for designing visualizations based on data-driven models. Interpretation refers to the facility with which an analyst makes inferences about the data through the lens of a model abstraction. Trust refers to the actual and perceived accuracy of an analyst's inferences. These considerations derive from our experiences developing the Stanford Dissertation Browser, a tool for exploring over 9,000 Ph.D. theses by topical similarity, and a subsequent review of existing literature. We contribute a novel similarity measure for text collections based on a notion of "word-borrowing" that arose from an iterative design process. Based on our experiences and a literature review, we distill a set of design recommendations and describe how they promote interpretable and trustworthy visual analysis tools.
materials and links
citation
ACM Human Factors in Computing Systems (CHI),
2012