Identifying Medical Terms in Patient-Authored Text: A Crowdsourcing-based Approach
abstract
Background and objective: As people increasingly engage in online health-seeking behavior and contribute to health-oriented websites, the volume of medical text authored by patients and other medical novices grows rapidly. However, we lack an effective method for automatically identifying medical terms in patient-authored text (PAT). We demonstrate that crowdsourcing PAT medical term identification tasks to non-experts is a viable method for creating large, accurately-labeled PAT datasets; moreover, such datasets can be used to train classifiers that outperform existing medical term identification tools.
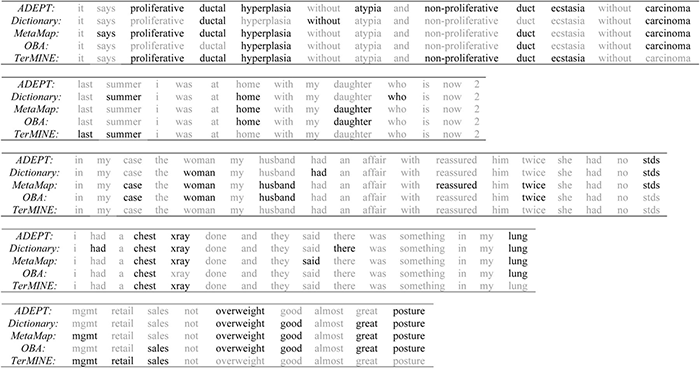
Materials and methods: To evaluate the viability of using non-expert crowds to label PAT, we compare expert (registered nurses) and non-expert (Amazon Mechanical Turk workers; Turkers) responses to a PAT medical term identification task. Next, we build a crowd-labeled dataset comprising 10 000 sentences from MedHelp. We train two models on this dataset and evaluate their performance, as well as that of MetaMap, Open Biomedical Annotator (OBA), and NaCTeM's TerMINE, against two gold standard datasets: one from MedHelp and the other from CureTogether.
Results: When aggregated according to a corroborative voting policy, Turker responses predict expert responses with an F1 score of 84%. A conditional random field (CRF) trained on 10 000 crowd-labeled MedHelp sentences achieves an F1 score of 78% against the CureTogether gold standard, widely outperforming OBA (47%), TerMINE (43%), and MetaMap (39%). A failure analysis of the CRF suggests that misclassified terms are likely to be either generic or rare.
Conclusions: Our results show that combining statistical models sensitive to sentence-level context with crowd-labeled data is a scalable and effective technique for automatically identifying medical terms in PAT.
materials and links
citation
J Am Med Inform Assoc,
2013